AI training is increasingly indispensable nowadays, in a context where the spread of artificial intelligence seems unstoppable and is gradually changing the way we live and work in every field.
However, AI technology still has some strong limitations: its ability to make decisions or perform tasks with little or no human intervention brings with it a major problem, that of so-called “hallucinations”.

To minimize hallucinations, it is necessary to develop models based on intensive AI training and testing processes, which require a huge amount of data. In this context, using a crowdsourced training mode can make a difference.
AI Hallucination, impact on users and causes
If you have ever used AI models, you will have seen, also several times, results that do not correspond to reality or that are not consistent with the input data provided
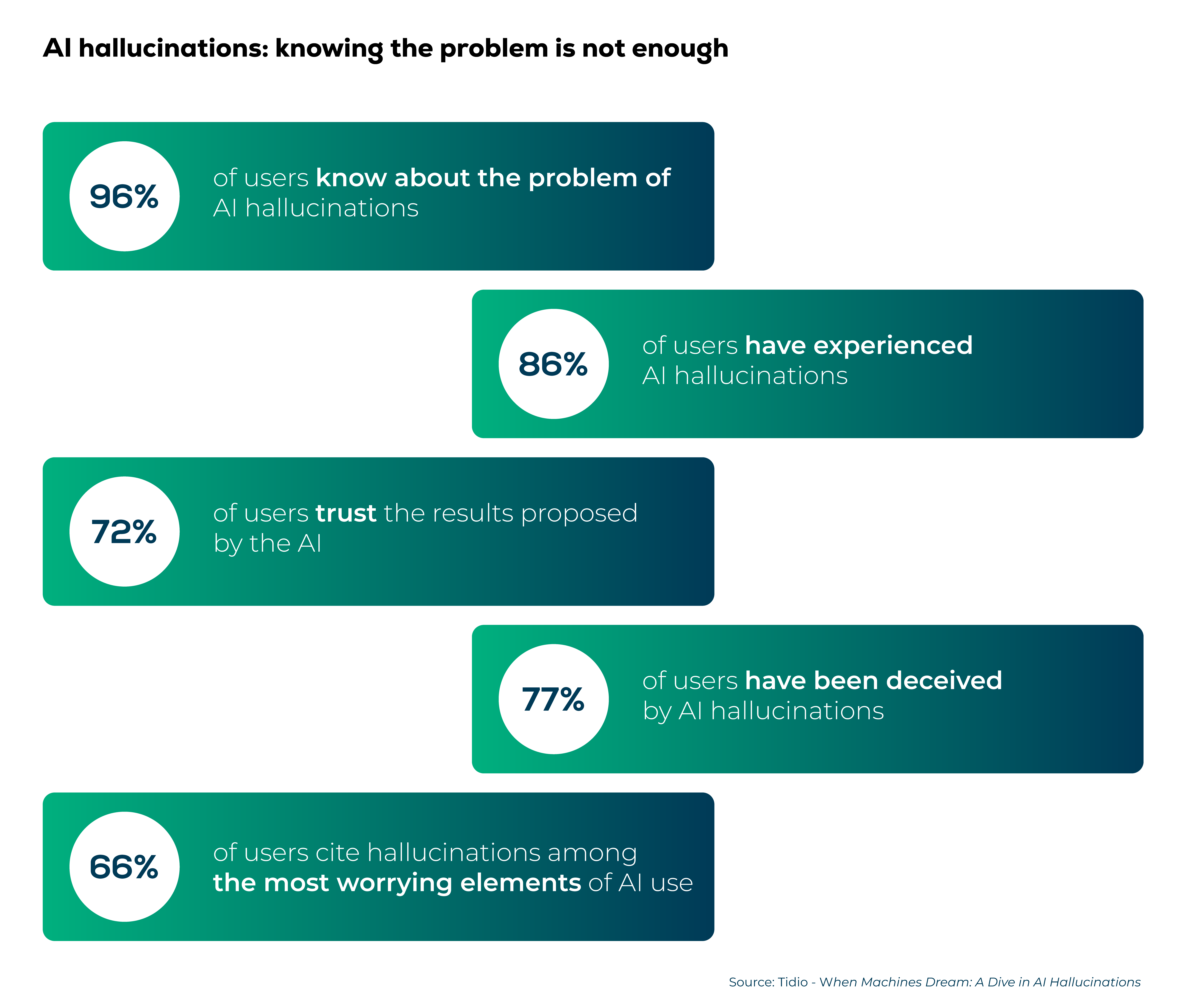
According to a study conducted by Tidio, while the majority of users are aware of what AI hallucinations are, it is surprising to see that about 77% of users have been deceived by them. Hallucinations are, in fact, one of the items of greatest concern to end users (66%).
But why does artificial intelligence sometimes give made-up or inaccurate answers?
AI hallucinations occur because the model sees or invents a pattern it is not trained on, and produces an imaginary response. Specifically, this occurs for several reasons, including:
- specific data sets (overfitting) that make the models too specialized and generate errors when new data are presented;
- poor quality data, not sufficiently diverse, damaged or with a lot of noise;
- biased data that could lead to replication bias, as well as generate inaccurate and unfair predictions.
Thus, limited, partial, out-of-date, biased data can compromise the reliability of AI applications.
How to overcome AI hallucinations: the Human-in-the-Loop approach
To overcome this hurdle, it is essential to adopt testing, validation and feedback strategies based on the Human-in-the-Loop (HITL) approach, thus placing humans within a virtuous circle in which models are trained, refined and monitored.
Through rigorous processes of testing and validation with human testers , the artificial intelligence system is exposed to a wide range of input data and scenarios to correct errors, improve data quality and ensure accurate and consistent predictions. This methodology helps identify and resolve potential problems in AI systems before they become significant and complex to remove.
AI training cannot be based solely on total automation. Man is still the protagonist, as he is the only one capable of adapting algorithms to new goals through experience and knowledge, elements still unknown to machines.
AI training, the advantages of crowdsourcing methodology
AI training in the crowdsourcing mode enables access to a global, heterogeneous community of people so as to enable successful training based on the Human-in-the-Loop approach and, at the same time, ensure:
- greater efficiency and convenience,
- an improvement in the accuracy and diversity of data used for training.
In fact, crowdsourcing training allows people from different parts of the world to be involved in collecting, categorizing, and validating data. This strategy has many advantages including:
- Flexibility, scalability, and speed:
with crowdsourcing, the AI training process can be enabled at any time, accessing a large audience of users that can be dynamically scaled as needed. This, in addition to reducing training and testing time, is particularly useful when AI models need to be frequently updated with new data.
- Cost reduction:
engaging a community, also iteratively, is more cost-effective than creating an in-house team dedicated to data collection, categorization, and validation. Developers will then have the opportunity to focus their attention on the models, evaluate their quality and adherence to requirements.
- Data quality:
thanks to the participation of people with different backgrounds, languages, and cultures, the data collected, categorized, and validated are characterized by quality, heterogeneous, and extremely diverse data. This is critical to training models capable of adapting in global contexts.

Crowdsourcing for reliable, trustworthy and accurate AI
Crowdsourcing, therefore, represents a powerful and flexible way to collect data needed for training and testing AI algorithms. The diversity and scalability of the data collected through this methodology, along with effective quality control practices, are indispensable elements in maximizing the quality of the algorithms.

The training and testing of AI algorithms requires a wide variety of data, including text, images, voice, handwriting, documents, biometric data, and much more. The crowd-based approach is particularly well suited for this purpose because it allows you to quickly collect data of different types and from various sources.
We at UNGUESS provide you with a community of real users, with the specific goal of providing the maximum number of datasets needed for optimal training. In this way, you can quickly obtain accurate and diverse data, thus improving the algorithm's ability to operate effectively in real-world contexts.
