L’AI training est de plus en plus indispensable de nos jours, dans un contexte où la diffusion de l'intelligence artificielle semble inéluctable et modifie peu à peu notre façon de vivre et de travailler dans tous les secteurs.
Cependant, la technologie de l'IA présente encore de sérieuses limites: sa capacité à prendre des décisions ou à effectuer des tâches avec peu ou pas d'intervention humaine s'accompagne d'un problème majeur, celui des dites « hallucinations ».

Pour minimiser les hallucinations, il est nécessaire de mettre au point des modèles basés sur des processus intensifs d'AI training et testing, qui requièrent une énorme quantité de données. Dans ce contexte, l'utilisation d'un mode de formation en crowdsourcing peut faire la différence.
Hallucination de l'IA, impact sur les utilisateurs et causes
Si vous avez déjà utilisé des modèles d'IA, vous avez été témoin, même à plusieurs reprises, de résultats qui ne correspondent pas à la réalité ou qui sont incohérents avec les données d'entrée fournies.
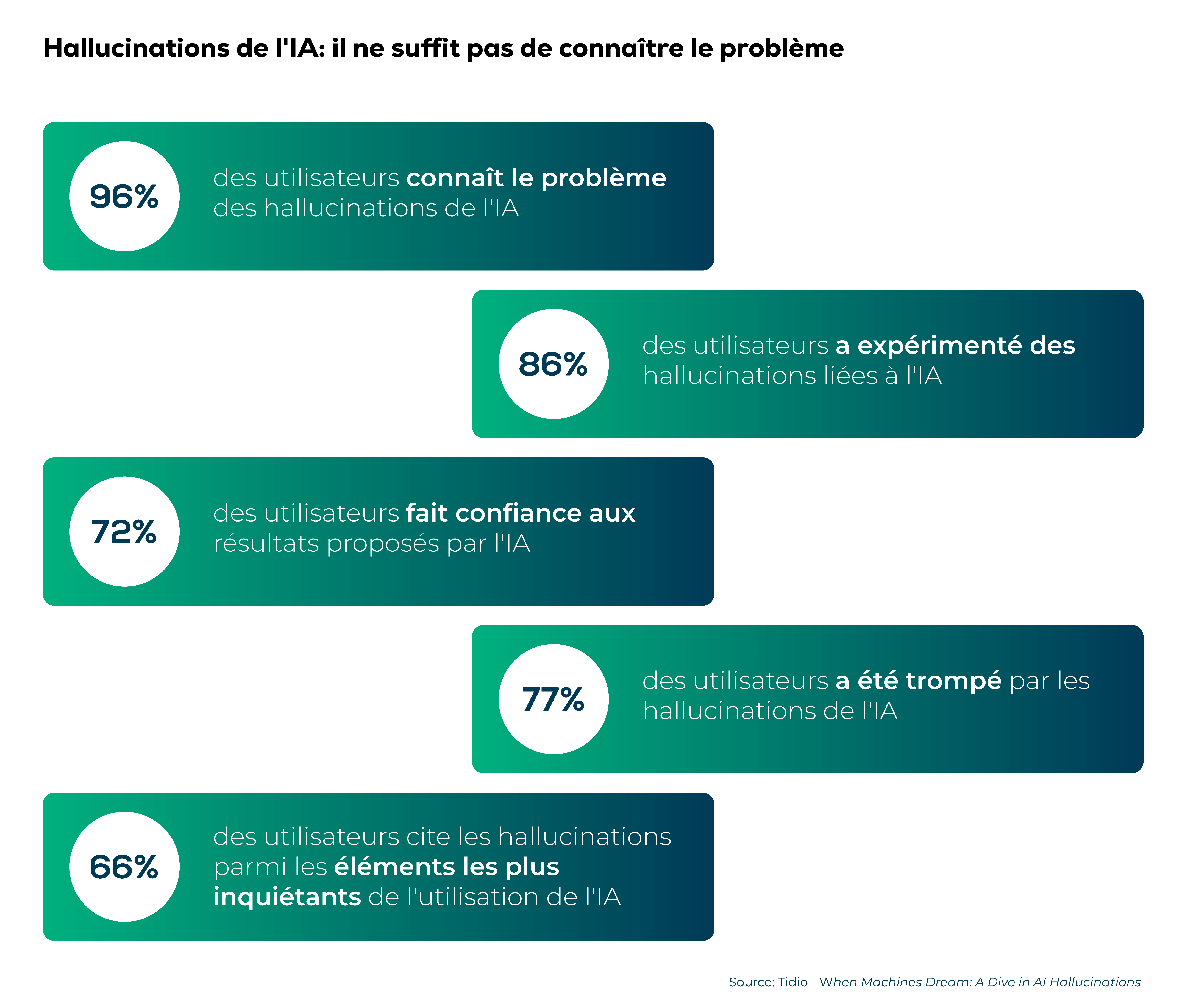
Selon une étude réalisée par Tidio, si la majorité des utilisateurs sait ce que sont les hallucinations de l'IA, il est surprenant de constater qu'environ 77 % des utilisateurs ont été trompés par ces hallucinations. Les hallucinations comptent parmi les éléments les plus préoccupants pour les utilisateurs finaux (66 %).
Mais pourquoi l'intelligence artificielle donne-t-elle parfois des réponses inventées ou inexactes ?
Les hallucinations de l'IA se produisent parce que le modèle voit ou invente un modèle sur lequel il n'a pas été formé et produit une réponse imaginaire. Cela se produit notamment pour plusieurs raisons, à savoir :
- des ensembles de données spécifiques (overfitting) qui rendent les modèles trop spécialisés et génèrent des erreurs lorsque de nouvelles données sont présentées ;
- les données de mauvaise qualité, pas assez diversifiées, endommagées ou très bruitées ;
- des données faussées qui pourraient mener à la réplication de biais, mais générer des prévisions inexactes et injustes.
Ainsi, des données limitées, partielles, obsolètes ou faussées peuvent compromettre la fiabilité des applications d'IA.
Comment surmonter les hallucinations de l'IA : l'approche Human-in-the-loop
Pour surmonter cet obstacle, il est essentiel d'adopter des stratégies de test, de validation et de retour d'information basées sur l'approche Human-in-the-Loop (HITL), plaçant ainsi les humains dans un cercle vertueux oùles modèles sont formés, affinés et contrôlés.
Grâce à des procédures rigoureuses de tests et de validation rigoureuse avec des testeurs humains, le système d'intelligence artificielle est exposé à un large éventail de données d'entrée et de scénarios afin de corriger les erreurs, d'améliorer la qualité des données et de garantir des prédictions précises et cohérentes. Cette méthodologie permet d'identifier et de résoudre les problèmes potentiels des systèmes d'IA avant qu'ils ne deviennent importants et complexes à éliminer.
Le training de l'IA ne peut pas se fonder uniquement sur une totale automatisation. L'homme tient les rêvnes, car il est le seul capable d'adapter les algorithmes à de nouveaux objectifs grâce à l'expérience et à la connaissance, éléments encore inconnus des machines.
Training AI, les avantages de la méthodologie du crowdsourcing
Le training AI en mode crowdsourcing permet d'accéder à une communauté mondiale et hétérogène de personnes, permettant ainsi une formation réussie basée sur l'approche Human-in-the-Loop tout en garantissant :
- une efficacité et une convivialité accrues,
- une amélioration de la précision et de la diversité des données utilisées pour le training.
Le crowdsourcing de la formation permet de faire participer personnes de différentes parties du monde à la collecte, à la catégorisation et à la validation des données. Cette stratégie présente de nombreux avantages, à savoir :
- Flexibilité, évolutivité et rapidité :
avec le crowdsourcing, le processus de training de l’IA peut être activé à tout moment, avec un accès à un large public d'utilisateurs qui peut être dynamiquement redimensionné en fonction des besoins. Outre la réduction du temps de formation et de test, cela s'avère particulièrement utile lorsque les modèles d'IA doivent être fréquemment mis à jour avec de nouvelles données.
- Réduction des coûts :
impliquer une communauté, même de manière itérative, est moins coûteux que de mettre en place une équipe interne dédiée à la collecte, à la catégorisation et à la validation des données. Les développeurs pourront ainsi se recentrer sur les modèles, évaluer leur qualité et leur conformité aux exigences.
- Qualité des données :
grâce à la participation de personnes d'origines, de langues et de cultures différentes, les données recueillies, catégorisées et validées se caractérisent par leur qualité, leur hétérogénéité et leur très grande diversité. Cela est essentiel pour former des modèles adaptables à des contextes mondiaux.

Le crowdsourcing pour une IA fiable, fondée et précise
Le crowdsourcing représente donc un moyen puissant et flexible de recueillir les données nécessaires pour former et tester les algorithmes d'IA. La diversité et l'évolutivité des données recueillies grâce à cette méthodologie, ainsi que des pratiques efficaces de contrôle de la qualité, sont des éléments indispensables pour maximiser la qualité des algorithmes.
La formation et le test des algorithmes d'IA nécessitent une grande variété de données, notamment du texte, des images, de la voix, de l'écriture manuscrite, des documents, des données biométriques et bien plus encore. L'approche crow-based est particulièrement adaptée à cette fin, car elle vous permet de recueillir rapidement des données de différents types et issues de diverses sources.
Chez UNGUESS, nous mettons à votre disposition une communauté d'utilisateurs réels, dans le but spécifique de fournir le nombre maximum de données nécessaires à une formation optimale. Vous pouvez ainsi obtenir rapidement des données précises et diversifiées, ce qui améliore la capacité de l'algorithme à fonctionner efficacement dans des contextes réels.
