Con questo articolo inauguriamo la rubrica per il blog di UNGUESS di Luca Giovenzana, CTO / CTPO e Agile Executive per viteSicure e Golee, oltre che appassionato di agile e tecnologia.
Beware the Brittle Dragon - parte 1
In principio era il caos. Estenuanti test manuali governavano il mondo, epidemie continue affliggevano la popolazione. Villani tester condannati a ripetere meccanicamente pesanti lavori si ammalavano della piaga di quel tempo: la regressione. Nelle campagne ogni tanto riaffiorava l’antica leggenda della Test Automation.
Si narrava che paesi lontani prosperassero e avessero sconfitto la piaga della regressione. Un giorno, finalmente, arrivò colui che avrebbe cambiato le sorti del mondo: L’eroe dell’Automation.![]()
![]()
Come nelle leggende l’eroe portò la soluzione a tutti i problemi, ma avvertì che una profezia li minacciava:

«Utilizzate la test automation con attenzione e rispettate la regola oppure un male più grande della regressione si sveglierà».
I villani cominciarono da subito a utilizzare la test automation e smisero di fare test manuali, e così l’epidemia di regressione cominciò a scomparire. Ma la regola era faticosa da applicare, così poco a poco smisero di seguirla e fecero test sempre più fragili. Ed ecco che la profezia si avverò; i test fragili svegliarono un Drago che seminò il panico e distrusse la test automation.
Così, i villani furono costretti a tornare alla vecchia e dura vita fatta di test manuali, per paura di risvegliare il Drago. La test automation fu abbandonata e la regressione tornò a regnare sovrana.
Morale della storia (spoiler)
Credo che ci siano molti parallelismi tra questa storia e il percorso di team che si sono avvicinati a strumenti di test automation per la prima volta. Ma qual’è la morale?
Non basta scrivere test automatici per averne effettivamente dei benefici.
Una piattaforma di test automation, per dare valore e offrire un reale ritorno rispetto all’investimento, deve avere varie caratteristiche ma sicuramente la più importante è l’affidabilità.
I test fragili - o brittle test - minano nel profondo la credibilità della test automation, nel resto dell’articolo ci concentreremo proprio su come evitarli.
In questo articolo ci riferiremo principalmente a un insieme di test di alto livello: User Interface, End to End dove il sistema sotto test è un ambiente di staging tipicamente completo.
Cosa è un “brittle” test?
Un test “brittle” è essenzialmente un test fragile, ovvero un test che si rompe facilmente. Spesso ci si riferisce a questa tipologia di test anche con il termine “flaky” che ne sottolinea l’inaffidabilità e l’esito non deterministico.
Un esempio classico è il test che fallisce, ritorna a funzionare, fallisce di nuovo e così via. Spesso questi cambi di esito avvengono senza modifiche delle funzionalità del prodotto o del test stesso. Il vero problema di questa tipologia di test è che non falliscono per reali problemi del sistema che si sta testando ma per problemi di come è effettuato il test, di come sono costruite le precondizioni o di come viene riprodotto il sistema da testare.
Normalmente le cause di questa fragilità sono da attribuirsi a:
- Accoppiamento forte con l’implementazione che rende facilmente obsoleto il test
- Ampio scope del test che aumenta la probabilità di un fallimento
- Scarsa qualità del test e del design in generale
- Problemi legati a fattori esterni rispetto al software sviluppato (infrastruttura, dati, sistemi esterni, ecc.)
Quali sono le conseguenze?
Alta percentuale di test falliti
La conseguenza più ovvia è l’alto numero di test falliti. Solitamente il problema ha origini nelle precondizioni del test, della suite o generali, queste, essendo condivise fanno fallire simultaneamente più test.
Un altro effetto che spesso si verifica è “l’effetto rollercoaster” ovvero un andamento ondulatorio nei risultati dei test (vedi immagine). Ovviamente questo non agevola l’analisi della situazione dal punto di vista della qualità delle varie versioni.
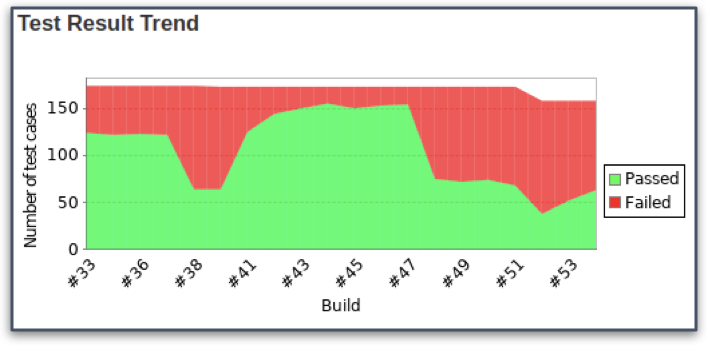
Alto costo di manutenzione
Se ci sono test che falliscono inevitabilmente vanno sistemati.
Prima però si deve analizzare il motivo del fallimento. Quando un test automatico fallisce, il modo più rapido per assicurarsi che sia per colpa di un bug è riprodurre lo stesso test in modo manuale.
Ma i test automatici non servono proprio a evitare test manuali?
A questo punto si cerca di capire l’origine del problema e finalmente si può provare ad applicare una correzione. Questo processo non è sempre semplice, data la difficoltà di riprodurre un comportamento non deterministico. Di conseguenza c’è molto lavoro per mantenere affidabile la suite di test automation, in aggiunta rispetto al normale costo di manutenzione ed espansione dovuto a nuove funzionalità e modifiche.
Fallimenti che nascondono bug
Vediamo una situazione reale: di notte gira una batteria di test (oltre 1000) sull’ambiente di staging che impiega diverse ore. Alla mattina si vuole procedere con un rilascio importante ma molti test sono falliti. Da una prima analisi il fallimento è dovuto a una precondizione nota per essere un po’ fragile.
Il business spinge per il rilascio, non c’è tempo di rilanciare tutti i test, cosa si fa?
Rilasciamo o no?
Potremmo essere propensi a rilasciare comunque dato che l’analisi ha evidenziato che i fallimenti sono da attribuirsi a una precondizione, non a un assert che fallisce.
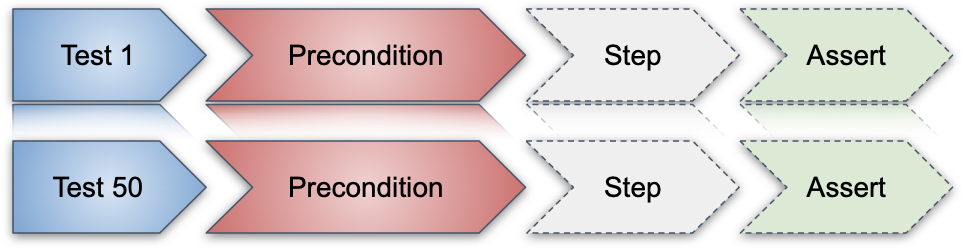
Ma un cognitive bias potrebbe portarci a pensare che i test sono falliti solo per questo motivo. E se invece il fail della precondizione nascondesse un fail reale dovuto a un bug?
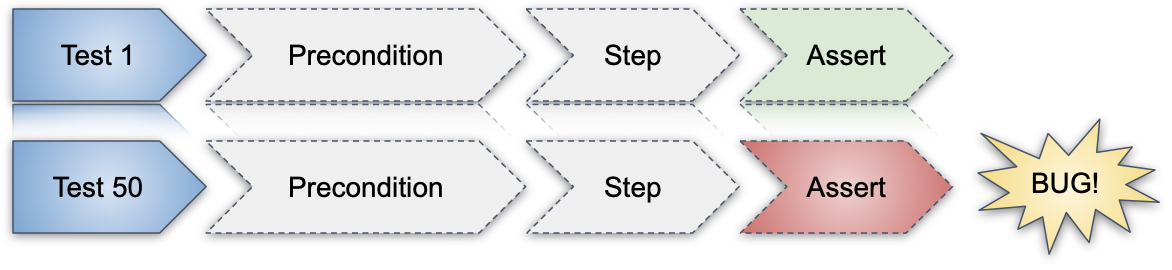
Questo è il genere di scelte che ci si trova a fare quando la test automation è fragile e poco affidabile.
Feedback inutile
Chiunque sia in carico di decidere se procedere con un rilascio in produzione, desidera consultare l’oracolo della test automation aspettandosi una risposta chiara alla domanda: “Possiamo rilasciare?”.
Se però la risposta è sempre “sì però…”, “forse”, “dobbiamo analizzare”, chiaramente l’oracolo perde la sua funzione è la sua risposta diventa inutile.
Bassa fiducia nei test

Ci sono diversi studi legati alla psicologia e alla criminologia che descrivono un fenomeno chiamato Broken Windows Theory. Questa teoria afferma che segnali visibili di criminalità e disordine civile incoraggiano atteggiamenti criminali e di disordine. Il nome deriva dal fatto che se una finestra di un edificio è rotta e non viene riparata presto tutte le altre finestre verranno rotte.
Quello che spesso succede nel mondo dei test è che se c’è un test che rimane rosso per diverso tempo, questo finirà presto in compagnia di altri e il fatto di avere test che falliscono diventerà una cosa normale.
Un circolo vizioso
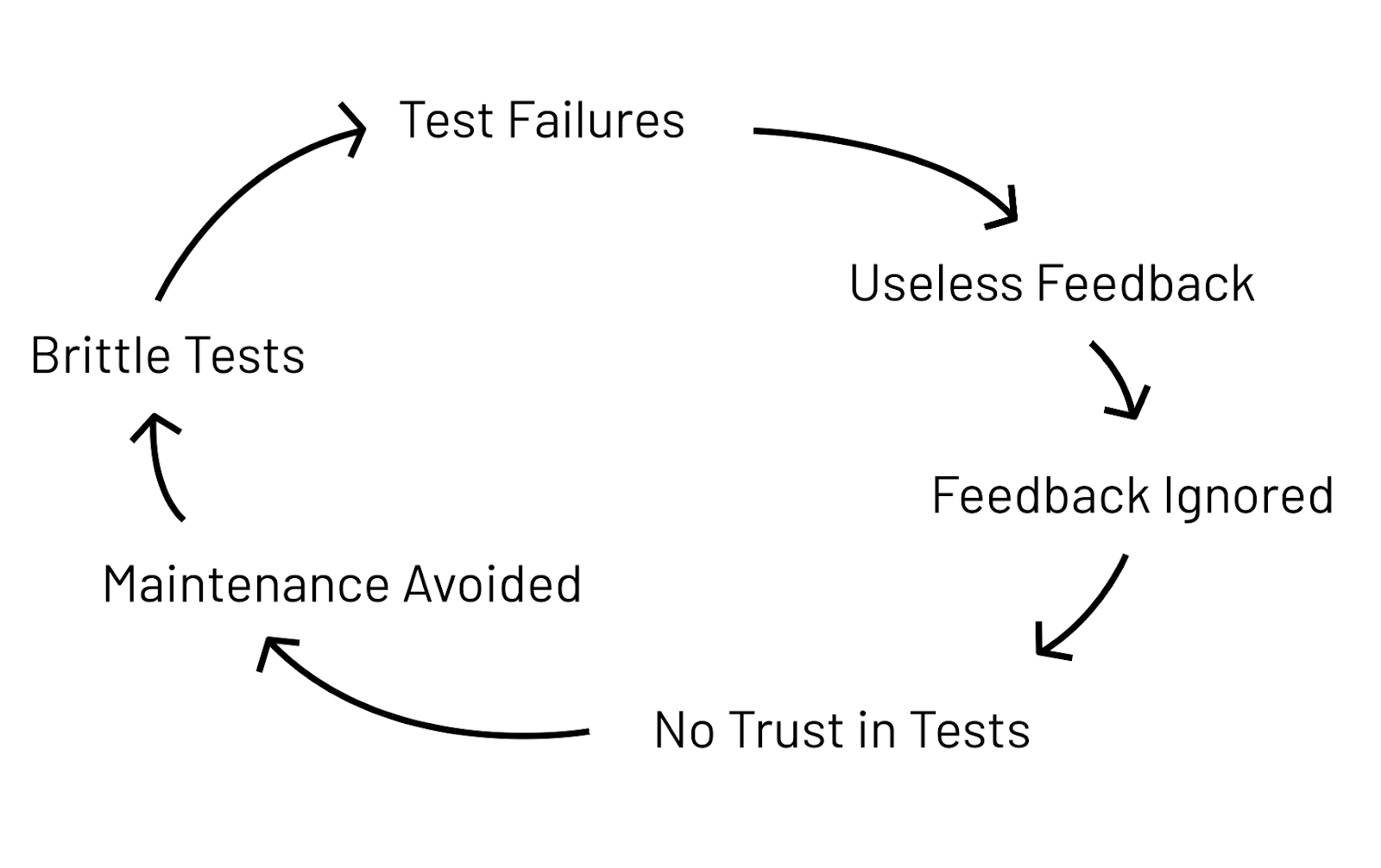
Se il feedback diventa inutile allora comincerà a essere ignorato, portando a un progressivo disinvestimento del team nella manutenzione a causa della perdita di fiducia nello strumento dei test automatici.
Risultato? Aumentano i test fragili che falliscono.
Il tempo speso nel creare la test automation è stato inutile, tanta fatica per niente. Il morale del team cala, ci sarà sempre meno interesse nello strumento e meno impegno nel mantenere ed evolvere la suite.
Nel prossimo episodio scopriremo cosa rende fragili i nostri test e come sconfiggere il Drago! Alla prossima.
Credits

I contenuti di questo articolo derivano da un talk creato e presentato insieme ad Angelo Caovilla durante il RobCon 2020 a Helsinki la conferenza mondiale di Robot Framework.
I disegni sono stati fatti grazie al supporto grafico di Matteo Villa.
 Luca Giovenzana è appassionato di tecnologia, agilità e startup. Inizia la sua carriera seguendo il suo interesse per Linux, l'Open Source e la Cyber Security. Dopo aver seguito l'intero scale up di CHILI, oggi Luca è CTO / CTPO e Agile Executive per viteSicure e Golee.
Luca Giovenzana è appassionato di tecnologia, agilità e startup. Inizia la sua carriera seguendo il suo interesse per Linux, l'Open Source e la Cyber Security. Dopo aver seguito l'intero scale up di CHILI, oggi Luca è CTO / CTPO e Agile Executive per viteSicure e Golee.