Nel precedente articolo (parte 1) abbiamo raccontato la storia di un team che inizia il suo viaggio alla scoperta dei test automatici. Inizialmente sembra tutto un sogno con i test manuali che diventano uno sbiadito ricordo, ben presto però si accorgono che i test automatici sono fuori controllo e causano più problemi di quelli che avrebbero dovuto risolvere. La profezia si avvera, il Drago si sveglia e si salvi chi può…
Cosa rende i test fragili? Come possiamo sconfiggere il Drago?
Abbiamo approfondito le caratteristiche dei cosiddetti test “brittle/flaky” fragili e le nefaste conseguenze che hanno sul team e sulla credibilità della test automation stessa.
Ora vediamo quali sono gli errori comuni, le caratteristiche dei test fragili e come renderli finalmente solidi.
Piramide o cono gelato?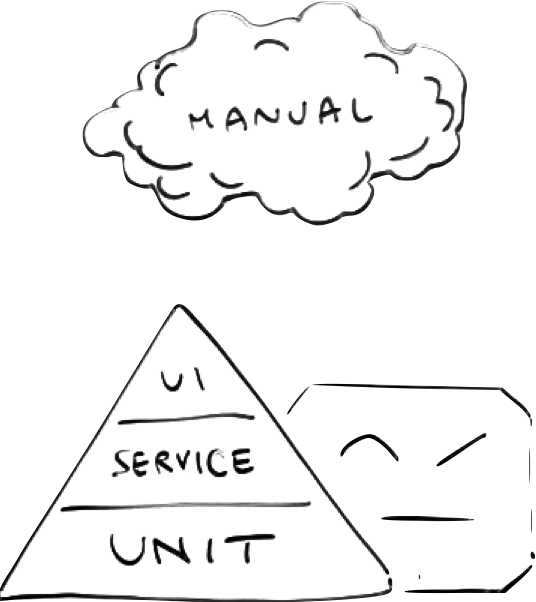
Una delle metafore più note rispetto a come organizzare suite di test automatici è quella della piramide dei test di Mike Cohn (Succeeding with Agile: Software Development Using Scrum). Qui trovate un articolo molto chiaro di Martin Fowler.
In breve la piramide descrive la distribuzione ideale dei test in base alla tipologia. La base larga del triangolo indica una prevalenza di test unitari contrapposta a una ridotta numerosità di test che interagiscono direttamente con l’Interfaccia Utente.
Il service level comprende tutte le tipologie di test che si posizionano tra la UI e i test isolati di classi. Tipicamente: API, integrazione e componente.
Spesso però la situazione è rovesciata con molti test end to end che usano l’interfaccia utente dando origine alla forma a “cono gelato”.
Tornando alla piramide, più si sale nella piramide e più la superficie sotto test aumenta e questo è in relazione diretta con la fragilità dei test. Un test unitario verifica una piccola porzione di codice, ed è per questo più difficile che si rompa. Un test end to end copre molte funzionalità, componenti, righe di codice perciò ha una probabilità più alta di fallire.
Se poi pensiamo alla rapidità con cui viene modificata l’interfaccia utente potremmo quasi dire che i test che interagiscono con l’interfaccia utente sono fragili per definizione.
Dal gelato alla piramide
Attenzione: non è sempre sbagliato avere un cono gelato!
Quando si approccia una codebase legacy, quindi senza test automatici secondo la definizione di Michael Feathers, spesso si cerca di aumentare la confidenza degli sviluppatori e del business aggiungendo test end to end.
In alcuni casi può essere l’unica alternativa percorribile dato che in questo genere di codebase è estremamente difficile aggiungere test unitari. Questa tecnica è efficace nel breve termine, ma l’obiettivo dovrebbe essere quello di ridurre il prima possibile questi test in favore di test più piccoli che stanno alla base della piramide.
È proprio questo il modo di rimettere in forma (piramidale) una suite di test automation: si deve cercare di spingere i test, o almeno parti di essi verso la base della piramide.
Spostando test verso il basso si riduce la fragilità, infatti un test API è solitamente meno fragile di un test UI e un test di componente o servizio è meno fragile di un test API. I test unitari dovrebbero essere i meno fragili di tutti.
Un primissimo passo che ho visto applicato spesso con successo è quello di spostare setup e teardown da test di UI a test API che sono più stabili e più veloci.
Il passo successivo è lavorare su test API. Spesso si trovano numerosi test API che verificano tutti i comportamenti possibili del sistema rendendo il tutto più complicato, lento e fragile.
In questo caso è possibile, probabilmente a fronte di refactoring progressivi, trasformare i casi testati via API in test interni al servizio, di componente o unitari.
I test API normalmente dovrebbero avere lo scopo di verificare l’integrazione tra lo strato di trasporto e il servizio descrivendo i casi d’uso principali, per i dettagli è più efficace lavorare alla base della piramide.
Di questa esperienza segnalo questo talk di un mio ex-collega, Nicola Mincuzzi.
Test manuali o esplorativi?
Nelle illustrazioni però sono indicati anche i test “manuali” di cui non abbiamo parlato.
I test manuali non sono il male, anzi sono test ad alto valore aggiunto, ma in questo caso io preferisco chiamarli test esplorativi.
Quando i test manuali sono invece un problema?
- quando sono gli unici;
- quando sono maggiori in numero rispetto a quelli automatizzati;
- quando sono ripetitivi;
- quando seguono una “checklist”;
- quando sono di non regressione.
Il test esplorativo invece è lavoro creativo del vero tester (o chi in quel momento indossa il cappello di tester) che deve trovare i limiti dei requisiti, i problemi di analisi, requisiti non funzionali (performance, sicurezza, usabilità e altri) immedesimandosi nel vero utente del sistema.

Chained tests
Un errore comune, quando si approcciano per la prima volta i test automatici, è quello di fare il test omnicomprensivo.
Un esempio pratico:
- comincio con un setup che apre il browser puntando a uno specifico url;
- poi faccio il test della registrazione di un nuovo utente;
- già che ho un nuovo utente posso anche effettuare la login;
- Ma ora che ho un utente loggato, per assicurarmi che sia veramente loggato, vuoi non fargli fare qualche cosa? Allora aggiungi un prodotto a carrello.
- A questo punto, vuoi non fargli fare il checkout? E ci metti un bel checkout.
Cosa verifica questo test? Quante assert ci sono in questo test? Se questo test fallisce quale potrebbe essere il motivo? È molto probabile che questo test avrà un nome poco chiaro.
Questi in realtà sono una catena di test diversi tutti dipendenti uno dall’altro; la buona pratica prevede però che ogni test sia totalmente indipendente. Più dipendenze implica più possibilità di failure e di conseguenza: fragilità.
Single Responsibility Principle
Le ragioni di fallimento diventano molteplici e diventa necessario analizzare gli errori per capire la radice del problema. Torna utile e attuale il Single Responsibility Principle, l'adagio di Robert C. Martin (Uncle Bob):
“There should never be more than one reason for a class to change”
Un principio che si applica pressoché immutato anche ai test, adattato in questo modo:
“There should never be more than one reason for a test to fail”![]()
Ogni test deve verificare una sola cosa, se fallisce un test leggendo il nome ho già chiaro il problema. Non preoccupiamoci troppo di ripetere più volte le precondizioni, la duplicazione si può facilmente risolvere creando utility di setup o builder.
I test saranno più lenti, vero, ma la soluzione non è fare meno test enormi, piuttosto spostare i test in basso nella piramide dove sono più veloci, ottimizzare le precondizioni, parallelizzare l’esecuzione (se sono indipendenti si può fare).
Avere più istruzioni di assert in un test generalmente non è una buona idea, potrebbe essere un indizio che sto testando più cose. Personalmente però non lo ritengo un dogma, a volte può essere utile fare più verifiche fintanto che la ragione di fallimento è la medesima.
Diamo una singola responsabilità anche alle utility per le precondizioni (setup) in modo da condividere solo quello che serve veramente. Il rischio è di fallire anche quando non sarebbe necessario e quindi di aumentare la fragilità.
Devo fare design?
Troppo spesso si considerano i test dell’applicazione codice di serie B. Non voglio dire che è più importante la suite di test rispetto al codice di produzione ma come in ogni cosa raccolgo quello che semino: se non investo nel design e nel refactoring i test diventeranno difficili da mantenere, fragili e inutili nel giro di poco.
Un esempio comune di scarso design dei test è l’utilizzo della sleep. Quando ci sono problemi di sincronizzazione, piuttosto che risolverli alla radice si procede a botte di quick and dirty. Ma l’effetto di una sleep è devastante perché aumenta forzatamente il tempo di esecuzione senza risolvere in modo definitivo il problema, a volte il ritardo potrebbe non bastare e la soluzione ovvia diventa aumentare la sleep entrando in un circolo vizioso.

Investiamo nella test automation
Dovremmo migliorare le nostre capacità di scrittura dei test esattamente come studiamo i framework, le best practices, i pattern che utilizziamo nello sviluppo delle funzionalità.
Come team concordiamo dei working agreements e delle best practices. Queste linee guida di Pekka Clark sono molto interessanti e applicabili in modo generico nonostante si riferiscano nello specifico a Robot Framework.
Una pratica per investire nei test, che da agilista consiglio, è il Pair Programming. A maggior ragione quando si parla di test è estremamente utile avere scambi di punti di vista sul comportamento desiderato del nostro sistema e sulla comprensione dei requisiti.
Questo pratica è ancora più vantaggiosa quando Tester e Developer lavorano insieme, il Tester si immedesimerà più facilmente nell’utente e potrà disegnare test di UI o di API prima ancora che vengano implementati, definendo i contratti di integrazione client / server. Il Developer contribuirà a questa fase immaginando il design del sistema con un approccio Test Driven Outside-In ovvero dalla periferia dell’applicazione fino al cuore delle logiche di dominio. Così facendo metterà da subito al centro l’utente con il suo comportamento e il design sarà costruito sulla base del requisito di business.
Un’altra pratica semplice ma che ritengo estremamente potente, se applicata con costanza, è la Boy Scout rule:
“Always leave the code you are editing better than you found it”
Iterare per piccole migliorie ogni volta che si interagisce con la codebase abilita un refactoring opportunistico che alla lunga mantiene in salute la suite di test, specialmente le parti più spesso utilizzate o modificate.
Nel prossimo episodio andremo a considerare aspetti più legati all’infrastruttura, agli ambienti e alle modalità di esecuzione delle test suite.
Bibliografia
-
Succeeding with Agile: Software Development Using Scrum - Mike Cohn
-
TestPyramid - Martin Fowler
-
Working Effectively with Legacy Code - Michael Feathers
-
How to write good test cases using Robot Framework - Pekka Clark
-
Clean Code - Robert C. Martin (Uncle Bob)
Credits

I contenuti di questo articolo derivano da un talk creato e presentato insieme ad Angelo Caovilla durante il RobCon 2020 a Helsinki la conferenza mondiale di Robot Framework.
I disegni sono stati fatti grazie al supporto grafico di Matteo Villa.
 Luca Giovenzana è appassionato di tecnologia, agilità e startup. Inizia la sua carriera seguendo il suo interesse per Linux, l'Open Source e la Cyber Security. Dopo aver seguito l'intero scale up di CHILI, oggi Luca è CTO / CTPO e Agile Executive per viteSicure e Golee.
Luca Giovenzana è appassionato di tecnologia, agilità e startup. Inizia la sua carriera seguendo il suo interesse per Linux, l'Open Source e la Cyber Security. Dopo aver seguito l'intero scale up di CHILI, oggi Luca è CTO / CTPO e Agile Executive per viteSicure e Golee.
Ringrazio Mauro Magnacavallo per la review.