UX & UI
Prototype testing, valida il tuo prodotto prima di svilupparlo!
Il prototype testing è una fase essenziale dello sviluppo del prodotto. Ecco di cosa si tratta e come funziona.
Scopri come l'AI training con il crowdsourcing può migliorare l'affidabilità degli algoritmi, ridurre le allucinazioni e ottimizzare le performance.
L’AI training è sempre più indispensabile al giorno d’oggi, in un contesto in cui la diffusione dell’intelligenza artificiale sembra inarrestabile e sta progressivamente cambiando il nostro modo di vivere e di lavorare in ogni settore.
Tuttavia, la tecnologia AI ha ancora dei forti limiti : la sua capacità di prendere decisioni o eseguire attività con un intervento umano minimo o nullo porta con sé un grosso problema, quello delle cosiddette “allucinazioni”.

Per minimizzare le allucinazioni, è necessario mettere a punto modelli basati su processi intensivi di AI training e testing, che richiedono una quantità enorme di dati. In questo contesto, l’utilizzo di una modalità di addestramento in crowdsourcing può fare la differenza.
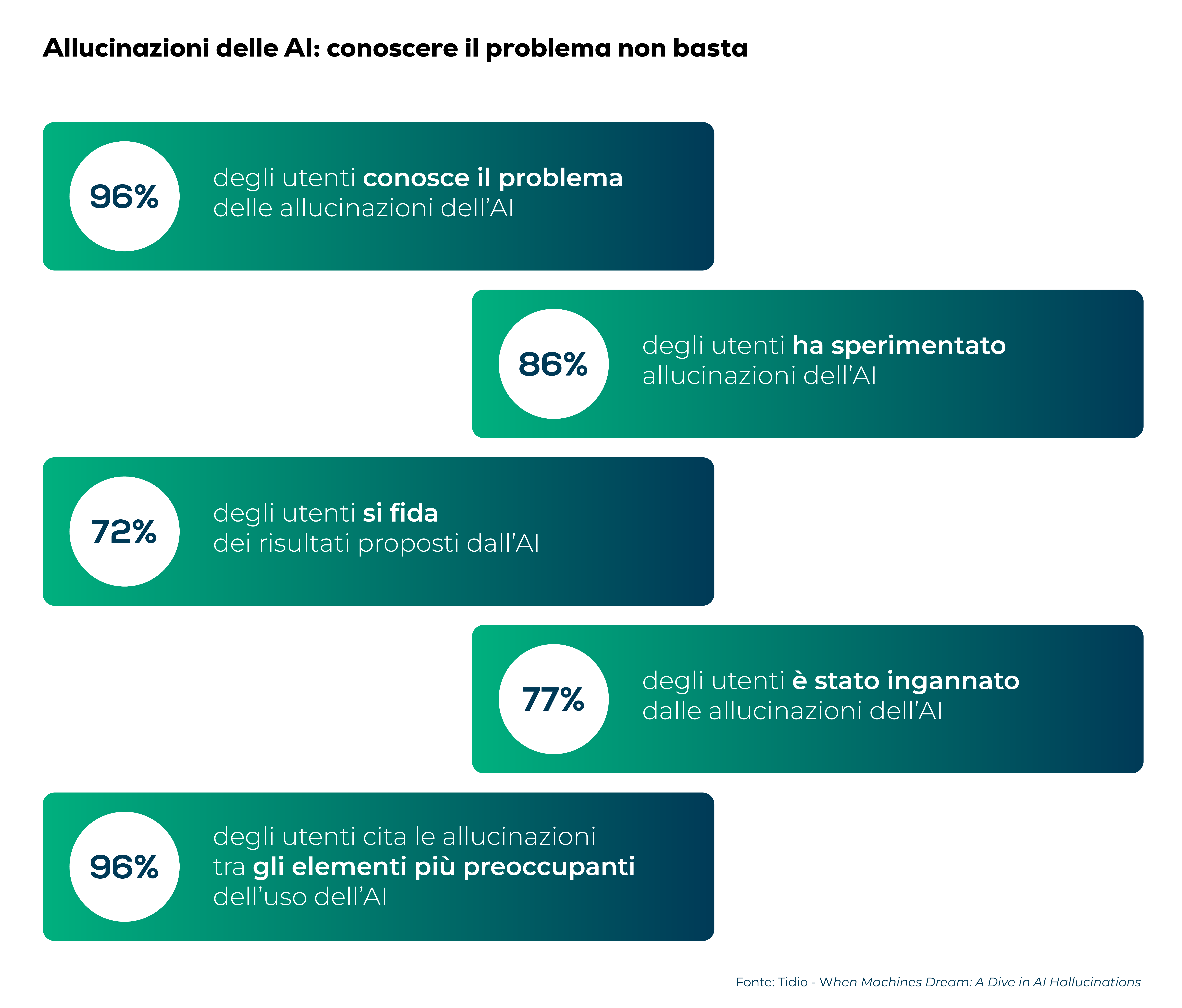
Se hai mai utilizzato modelli AI, ti sarà capitato, anche più volte, di assistere a risultati che non corrispondono alla realtà o che non sono coerenti con i dati di input forniti.
Secondo uno studio realizzato da Tidio, se da un lato la maggioranza degli utenti è a conoscenza di cosa siano le allucinazioni dell’AI, dall’altro è sorprendente vedere che circa il 77% degli utenti ne è stato ingannato. Le allucinazioni sono, di fatto, uno degli elementi che maggiormente preoccupano gli utenti finali (66%).
Ma perché l’intelligenza artificiale a volte dà risposte inventate o non accurate?
Le allucinazioni dell’AI si presentano perché il modello vede o inventa uno schema su cui non è addestrato, e produce una risposta immaginaria. In particolare, tutto ciò si verifica per diversi motivi, tra cui:
Quindi, dati limitati, parziali, non aggiornati, distorti possono compromettere l’affidabilità delle applicazioni AI.
Per superare questo scoglio, è indispensabile adottare strategie di testing, validazione e feedback basate sull’approccio Human-in-the-Loop (HITL), ponendo quindi gli esseri umani all’interno di un circolo virtuoso in cui i modelli vengono addestrati, perfezionati e monitorati.
Grazie a rigorosi processi di test e validazione con tester umani , il sistema di intelligenza artificiale viene esposto a un’ampia gamma di dati di input e scenari per correggere gli errori, migliorare la qualità dei dati e garantire previsioni accurate e coerenti. Questa metodologia aiuta a identificare e risolvere potenziali problemi nei sistemi AI prima che diventino significativi e complessi da rimuovere.
L'AI training non può essere basato solamente su una totale automazione . L’uomo è ancora protagonista, in quanto è l’unico capace di adattare gli algoritmi a nuovi obiettivi attraverso esperienza e conoscenza, elementi ancora sconosciuti alle macchine.
L'AI training in modalità crowdsourcing abilita l’accesso a una platea eterogenea di persone, così da consentire un addestramento di successo basato sull’approccio Human-in-the-Loop e, al tempo stesso, garantire:
Il crowdsourcing dell’addestramento permette infatti di coinvolgere persone provenienti da diverse parti del mondo per raccogliere, categorizzare e validare dati. Questa strategia presenta numerosi vantaggi tra cui:
con il crowdsourcing è possibile abilitare in qualsiasi momento il processo di AI training, accedendo a una vasta platea di utenti che può essere dinamicamente ridimensionata sulla base delle necessità. Ciò, oltre a ridurre i tempi di addestramento e testing, è particolarmente utile quando si ha bisogno di aggiornare frequentemente i modelli AI con nuovi dati.
coinvolgere una community, anche in modo iterativo, è più economico rispetto alla creazione di un team interno dedicato alla raccolta, categorizzazione e validazione dei dati. Gli sviluppatori avranno così la possibilità di focalizzare la propria attenzione sui modelli, valutarne la qualità e l’aderenza ai requisiti.
grazie alla partecipazione di persone con background, lingue e culture diverse, i dati raccolti, categorizzati e validati sono caratterizzati da dati di qualità, eterogenei ed estremamente diversificati. Questo è fondamentale per addestrare modelli capaci di adattarsi in contesti globali.

Il crowdsourcing rappresenta, quindi, una modalità potente e flessibile per la raccolta di dati necessari all'AI training. La diversità e la scalabilità dei dati raccolti tramite questa metodologia, insieme a pratiche efficaci di controllo qualità, sono elementi indispensabili per massimizzare la qualità degli algoritmi.

L'addestramento e il testing degli algoritmi AI richiedono un’ampia varietà di dati, inclusi testo, immagini, voce, scrittura a mano, documenti, dati biometrici e molto altro. L’approccio crowd-based è particolarmente adatto a questo scopo perché ti permette di raccogliere rapidamente dati di diversi tipi e da varie fonti.
Noi di UNGUESS ti mettiamo a disposizione una community di utenti reali, con il preciso obiettivo di fornire il massimo numero di set di dati necessari per un addestramento ottimale. In questo modo, puoi ottenere rapidamente dati accurati e diversificati, migliorando così la capacità dell'algoritmo di operare efficacemente in contesti reali.

Il prototype testing è una fase essenziale dello sviluppo del prodotto. Ecco di cosa si tratta e come funziona.
Non serve solo avere buoni strumenti di sviluppo tecnico per creare prodotti o servizi di successo: il segreto è saper ascoltare il mercato. Ecco...
I KPI di product management aiutano a comprendere e definire il successo di un prodotto a 360 gradi. Ecco come fare
Il benchmark test di prodotto è in grado di fornirti informazioni su cui costruire il tuo vantaggio competitivo. Ecco come fare